Frecuentemente, trabajando con datos en salud, nos encontraremos con la necesidad de utilizar información extraída de nuestros sistemas productivos para hacer análisis, preparación de informes, cruce con otras fuentes de información, etc. A veces tendremos la suerte de que los datos a utilizar vengan en un formato tabular (Excel, separado por comas, o similar) que podamos utilizar de manera más o menos directa. Pero otras veces, la información que necesitamos utilizar puede venir en un formato procesable por máquinas, pero no fácilmente tabulable y utilizable para los fines que menciono antes; por ejemplo, puede ser que hagamos una extracción de un sistema que use bases de datos no relacionales para su persistencia, y lo que obtengamos sea uno o varios archivos JSON (JavaScript Object Notation). En otras ocasiones, puede ser que tengamos que trabajar con archivos XML (eXtensible Markup Language) como fuente de información.
Ambos tipos de formatos están muy bien descritos y documentados, y cuentan con muchas características que los hacen sumamente apropiados para el intercambio de información entre sistemas. Otra virtud es que ambos son, en términos generales, legibles y entendibles para los seres humanos; basta con abrirlos en un buen editor de texto, y podremos ver los datos que contienen, junto con su estructura:


El mismo conjunto de datos, representado en formato XML y JSON.
Ambos ejemplos tomados de opensource.adobe.com (http://opensource.adobe.com/Spry/samples/data_region/NestedXMLDataSample.html)(http://opensource.adobe.com/Spry/samples/data_region/JSONDataSetSample.html)
Descarga directa a estos archivos de ejemplo: XML y JSON
Sin embargo, una cosa es poder verlos, buscar en ellos, etc. en un editor de texto, y otra es poder convertirlos en un formato tabular para poder hacer otras cosas con ellos, como por ejemplo obtener estadísticas, agruparlos, filtrar información, etc. Felizmente, hay varias herramientas que podemos utilizar para lograr esto, y una de ellas, sumamente potente, es muy posible que ya la tengamos disponible en nuestros equipos. Se trata de Microsoft Power Query:

Power Query es una herramienta propietaria de Microsoft, que permite acceder, transformar e importar datos provenientes de cientos de fuentes distintas, incluyendo conexión directa a muchos motores de bases de datos, y a formatos de información como los que mencionamos más arriba. Es muy versátil, y es capaz de importar datos con estructura muy compleja con facilidad. En este artículo me centraré en la importación de XML y JSON, pero en artículos futuros escribiré, además, algunos ejemplos de cómo hacer transformaciones de tipos de datos, incorporación de nuevas columnas de datos calculadas a partir de los ya existentes, y otras funciones que pueden ser de muchísima ayuda para los que trabajamos todos los días con información.
Power Query viene incluido cuando se instala Excel 2016 y posterior, y se encuentra disponible gratuitamente como una extensión para Excel 2010 y 2013. Entonces, sin más, vamos a usarlo para cargar estos datos en un formato que podamos utilizar.
Requisitos antes de continuar:
a. Microsoft Excel
b. Microsoft Power Query (viene instalado con Excel 2016 o superior, debe instalarse por separado con versiones anteriores, ver link más arriba)
c. Archivos XML y JSON a utilizar como fuente de datos (pueden ser los vinculados más arriba)
1. Cargando un archivo XML con estructura anidada
El problema que puede presentar el cargar un archivo XML es que, por su naturaleza, este formato puede tener datos con una estructura anidada. Nuestros archivos de ejemplo (de acuerdo, no tienen nada que ver con salud aparte de su efecto deletéreo en la misma cuando los comemos  ; pero son muy prácticos porque ilustran muy bien las características típicas con que nos encontraremos con estos formatos) describen un catálogo de pastelería, que contiene distintos tipos de pasteles (donuts, barras, etc.), cada una con distintas opciones de masa (batters) y con una selección de agregados (toppings) posibles. Además, algunos de ellos (no todos) pueden llevar algún tipo de relleno. Esta estructura se encuentra “anidada” (con elementos dentro de otros elementos en la jerarquía del XML) que, a primera vista, hace difícil el trabajo de importación a una única tabla. Sin embargo, como veremos, es perfectamente posible.
; pero son muy prácticos porque ilustran muy bien las características típicas con que nos encontraremos con estos formatos) describen un catálogo de pastelería, que contiene distintos tipos de pasteles (donuts, barras, etc.), cada una con distintas opciones de masa (batters) y con una selección de agregados (toppings) posibles. Además, algunos de ellos (no todos) pueden llevar algún tipo de relleno. Esta estructura se encuentra “anidada” (con elementos dentro de otros elementos en la jerarquía del XML) que, a primera vista, hace difícil el trabajo de importación a una única tabla. Sin embargo, como veremos, es perfectamente posible.
En primer lugar, debemos abrir un libro de Excel, con una hoja en blanco en la cual importaremos los datos del XML (puede ser un libro nuevo, o bien uno existente, con una hoja en blanco creada para este fin). Con esta hoja en blanco seleccionada, debemos hacer clic en la pestaña “Datos”, y luego las opciones “Obtener datos” > “Desde un archivo” > “Desde un archivo XML”:


Hecho esto, nos aparecerá un diálogo para elegir el archivo XML que queremos importar. Abrimos el archivo deseado, y eso iniciará el asistente de Power Query:

Como podemos ver, a la izquierda se muestra el tipo de elemento “base” contenido dentro de este XML. Hacemos un clic sobre el mismo, y podemos ver la estructura general de los datos:

Si nuestro XML fuese muy simple, y sólo contuviese un listado de elementos base, sin otros elementos “hijos” de los primeros, con este paso estaríamos listos y podríamos simplemente hacer clic en el botón “Cargar” para obtener nuestros datos en Excel. Sin embargo, tal como en este ejemplo, la realidad suele ser más compleja. En este caso, vemos que hay otros elementos “hijos” anidados dentro de los elementos de base, que se muestran en la previsualización con la palabra “Table”. Eso quiere decir que vamos a tener que desmenuzar un poco más la información. Para esto, vamos a elegir la opción “Transformar datos”, que nos permitirá desglosar y elegir qué datos conservar y de qué manera. Para esto, elegimos el botón “Transformar datos”, que abrirá el editor de Power Query:

Como podemos ver, Power Query importó los elementos base del XML, poniendo tanto el contenido de estos elementos y sus atributos como columnas de la tabla. Para aquellos listados de elementos anidados, los muestra con la etiqueta “Table”. Podemos ver una previsualización de los subelementos en cada una de estas celdas haciendo clic en la celda misma (NO en la palabra “Table”, sino que en el espacio en blanco de la celda; hacer clic en la palabra expandirá esa celda únicamente, que no es lo que queremos ahora):

Ojo, que en algunos casos, la previsualización no nos ayudará de manera inmediata. En este caso, por ejemplo, la columna “Batters”, en su previsualización, nos muestra… Otra “Table”. Esto se debe a que, en el XML de origen, cada elemento <item> contiene un elemento hijo <batters>, que a su vez contiene una lista de elementos hijos <batter>. No así con la columna “Topping”, porque en el XML, el listado de <topping> es hijo directamente de cada <item>. Suena complicado, pero haciendo los pasos y explorando la estructura de los datos se va haciendo más transparente.
Así como está, la tabla no contiene toda la información que necesitamos. Queremos “expandir” estas tablas hijas, de modo de tener toda la información que necesitamos. Para hacer esto, usaremos el botón “Expandir”, que está ubicado en el encabezado de todas las columnas que tienen datos hijos:


Este botón nos dará control sobre qué columnas queremos expandir, y más aún, podremos elegir qué campos de datos son los que realmente nos interesa recuperar de esa expansión (como veremos, no necesariamente los necesitamos todos). Hagamos clic sobre el botón de expandir de la columna “batters”:

Tal como nos pasó al intentar visualizar, el expandir la columna “batters” me muestra un elemento hijo, “batter”. Esto es normal. Hacemos clic en “Aceptar”, y la columna “batters” será reemplazada por una nueva columna llamada “batters.batter”. Esta sí la podremos previsualizar:

Expandimos esta nueva columna, y ahora sí, nos mostrará los campos que es posible incluir en la expansión. Como vimos en la previsualización, esta tabla de elementos hijos tiene dos campos: uno, de texto, que contiene los nombres propiamente tales de los tipos de masa, y otro, un id numérico. Para efectos de este ejemplo, nos interesa solamente recuperar el nombre de las masas, por lo que desmarcaremos el id antes de hacer clic en Aceptar:

La columna se expandió, y esto agregó, en este caso, varias filas nuevas. Para cada elemento base, se agregaron columnas para cada uno de sus subelementos “batter”. Si hubiésemos elegido más de un campo de datos en la expansión de “batter”, se habrían agregado columnas también, una para cada campo expandido.
La columna “topping” la podemos expandir en un solo paso, por lo mencionado antes. La columna “fillings”, igual que la de “batters”, tendremos que expandirla en dos pasos. Nosotros tenemos libertad completa de decidir qué columnas expandir, y qué campos incluir en la expansión.
No hay que tener miedo de experimentar con las expansiones de campos; en todo momento, podremos editar o anular cualquiera de los pasos que vamos haciendo en el editor de Power Query. Esto lo podemos ver en el panel llamado “PASOS APLICADOS”, que contiene todo el historial de las transformaciones de datos realizadas:

En este panel, podremos anular cualquiera de los pasos aplicados haciendo clic en la “X” a la izquierda del paso, o bien, editar lo realizado en ese paso, con el engranaje a la derecha. Con esto último, por ejemplo, podremos incluir un campo que antes hayamos omitido en la expansión.
Cuando estemos conformes con la tabla de datos obtenida, haremos clic en el botón “Cerrar y cargar”. Esto llevará a cabo el proceso de importación y tendremos los datos disponibles en nuestra hoja de Excel:


Y listo. Hemos importado datos de una fuente XML, con una estructura anidada, que ahora podemos usar aplicando filtros, cargar en una tabla dinámica, cruzar contra otras tablas de datos, etc. Pero la magia no termina aquí: la consulta de Power Query, que extrae los datos del XML de origen queda guardada en el libro de Excel. Esto quiere decir que, posteriormente, si el archivo XML de origen se actualiza con nueva información, podemos volver a cargarla a nuestro Excel ¡sin tener que realizar la consulta nuevamente! En Excel, veremos en esta hoja un panel a la derecha llamado “Consultas y conexiones”. Ahí veremos que hay una consulta, que es la que construimos con Power Query. Al deslizar el mouse sobre ella veremos varias opciones (entre ellas, la de editar la consulta realizada), y también un botón para actualizar los datos:

Haciendo clic en este botón, se recargarán los datos más recientes contenidos en el archivo de origen (que debe permanecer en la misma ubicación en que estaba originalmente para que esto funcione, eso sí). Podemos experimentar cambiando algún dato en el XML y actualizando los datos.
2. Cargando un archivo JSON
La carga de un archivo JSON, en lo fundamental, no es tan distinta al proceso que ya vimos de cargar un XML, con algunas pequeñas salvedades. La primera, por supuesto, es que debemos seleccionar la fuente JSON al obtener datos:

A diferencia de la importación del XML, que intentaba determinar la tabla base a cargar, en JSON tendremos que navegar por la estructura de una manera un poco distinta hasta llegar al listado de elementos que serán la base de nuestra tabla. Al iniciar el proceso, veremos lo siguiente con nuestro archivo JSON de ejemplo:

Si previsualizamos la única celda disponible, veremos que sólo nos adelanta que contiene una lista. Haremos clic en la palabra “Record” al interior de la lista:
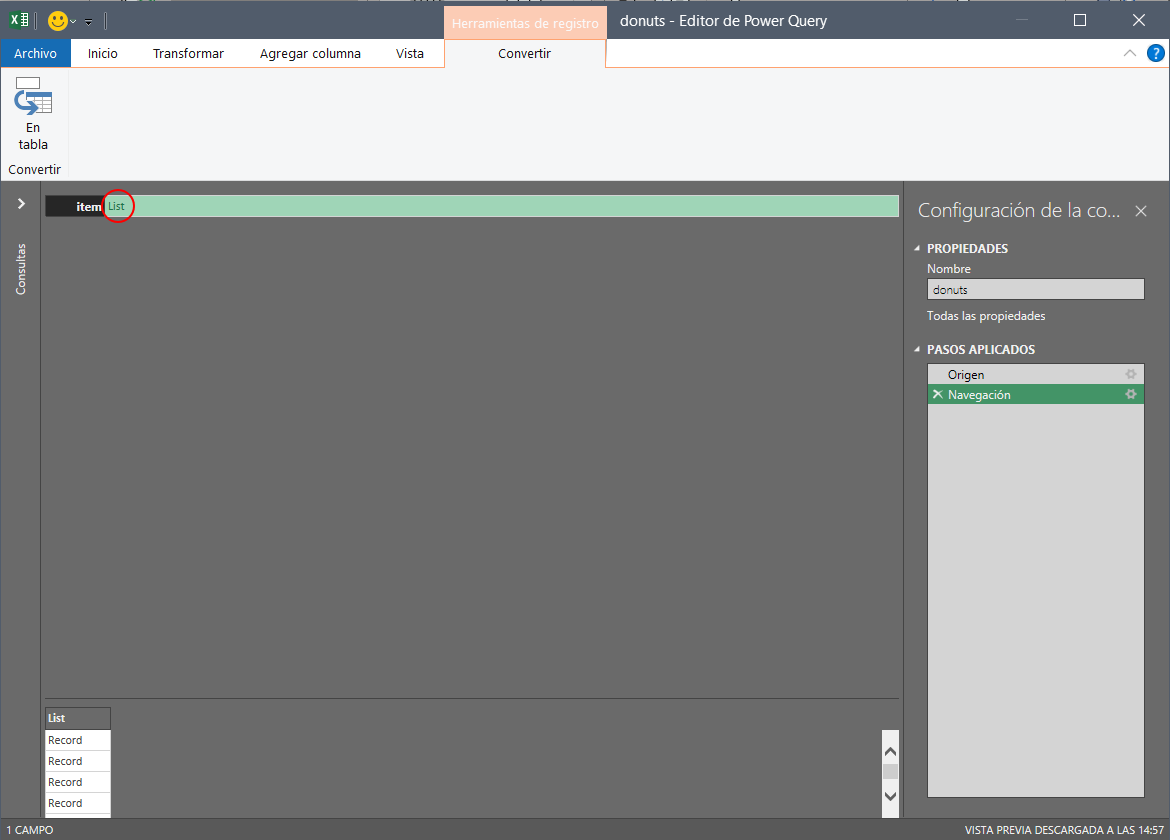
Avanzamos algo… Pero no mucho. Ahora, al intentar previsualizar, vemos que tenemos una lista de elementos “Record”. Hacemos clic en la palabra “List” en la celda:

Ahora sí, podemos previsualizar cada uno de los registros del listado. Éste es el nivel desde el que queremos construir nuestra tabla. Entonces, podemos hacer clic en el botón “A la tabla”, arriba a la izquierda. En el diálogo que aparece, dejamos las opciones por defecto, y hacemos clic en aceptar:


Argh… Nos aparece una tabla, con solamente filas que contienen “Record”… No es lo que queríamos, por supuesto… Pero, si nos fijamos, veremos que es posible expandir la columna. La expandimos, y…
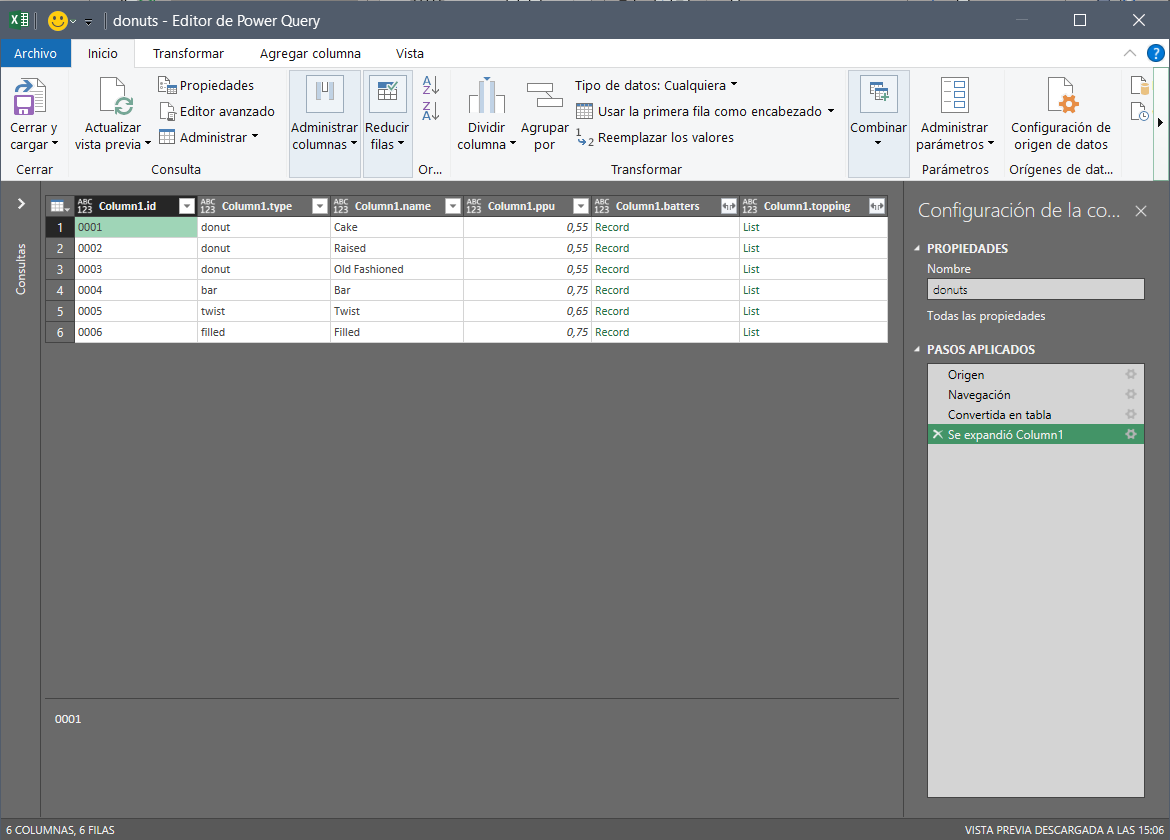
Finalmente, tenemos una estructura muy parecida a con la que partimos el ejemplo de XML. De aquí en adelante, podremos ir expandiendo las columnas que queramos, de exactamente la misma manera que antes. Según la estructura de los datos de origen (especialmente el nivel de anidamiento de cada elemento), a veces tendremos que hacer dos expansiones de cada columna para llegar a los datos, pero la lógica es exactamente la misma.
Espero que este mini tutorial sea de utilidad; esta es una herramienta bastante desconocida por mucha gente y, sin embargo, muy poderosa y ampliamente instalada en muchos equipos, dada la ubicuidad de Excel. En un artículo futuro escribiré acerca de cómo transformar y calcular datos nuevos al momento de definir conexiones con Power Query.
